目前國內鮮有檢出限的細致文獻報告,而分析化學的重要問題之一就是回答我們所采用方法能檢出的*小濃度或量��。鑒于儀器網信息網論壇越來越多關于檢出限的問題����,以及各種儀器在檢測分析時都會經常遇到的問題,本文以及整理常規計算檢出限的思路��。雖然文章稍顯艱澀����,但對于有興趣探究檢出限深度的人士,不失為較好的開卷之物��。歡迎對這個方面感興趣的朋友一起交流切磋��。
任何科學定義的討論必須建立在其相關術語統一規范的基礎上����。
假如你我雖然使用同樣的單詞/詞語�,但該單詞/詞語的含義并未達到一致的��,那么接下來的討論可能就沒有任何意義�。
IUPAC、ISO等國際組織首先嚴肅的認識到統一檢出限術語的重要意義�����,經過多年討論��,于1995年發布IUPAC Recommendations和 ISO/DIS 11843規范?��,F有的檢出限的理論定義基本都以此為藍本�。這里要特別指出的是美國統計學家Lloyd A. Currie�����,正是由于他的**努力推動了檢出限相關理論的發展���,IUPAC和ISO關于檢出限的理論基礎都來至于他的理念。盡管德國人Kaiser被認為是檢出限概念的創始人���,但他所提出的檢出限缺乏統計學上的完備性���。
我們首先來看看IUPAC對于檢出限的定義:
“ 檢出限(Detection limit or limit of detection)為某特定方法在給定的置信度內可從樣品中檢出待測物質的*小濃度或量���。 理解該定義的關鍵詞是某特定方法和置信度。
IUPAC認為檢出限是化學測量過程(chemical measurement process)或特定方法的特征�,與其它諸如特異性、精密度�,準確度、線性范圍和穩健度等共同刻畫化學測量過程的特點�。這個意義上講IUPAC檢出限準確說是方法檢出限(Method detection Limit)。
強調方法檢出限的意義:
我們將要重點關注的是方法空白���,即以一定的置信度與方法空白相區別的*小濃度或量為檢出限����。一般意義上講����,我們做檢出限就是先測定空白,然后用統計的方法來判斷能夠與空白相區別的*小濃度和量����。由于任何測量值都是一個統計量,有平均值和標準偏差等統計參數����,在判斷與空白相區別的時候我們就必須采用置信度的方法���。
圍繞檢出限的術語有很多,諸多的英語術語再加上翻譯上的差異�,讓這樣的術語可以羅列一大篇。比如檢測限��,*低檢出濃度等��。既然IUPAC作出了檢出限相關概念的推薦��。所以建議在以后工作中為方便大家的交流和討論�����,盡量使用檢出限(Detection limit or limit of detection)����,定量限(quantification limit)這樣的規范的術語�。
理解檢出限的理論核心必須建立在三個重要前提的理解上面:
1、對測量的統計特性的理解上�,正如我們所指出的那樣,測量總是帶有一定的隨機誤差�����,這種隨機誤差決定測量的結果總是一個帶有分布的范圍,可以用特殊的分布函數來描述�����。
2����、現有的測量基本是相對測量,我們必須先區分儀器響應信號(信號域)和濃度或量(濃度域)的差別�。不管是信號域還是濃度域都同樣具有統計的特性,我們往往首先得到信號域的結果����。
3、統計學上的兩類錯誤���。任何判斷在統計學上都會犯兩類錯誤�。針對判斷檢出限與空白相比較的例子�����,如果我們說空白信號/濃度比我們設定的檢出限低�,這個時候就可能犯I型錯誤(α)�;如果我們說我們設定的檢出限比空白信號/濃度高�����,這個時候就可能犯II型錯誤(β)����。
IUPAC(95版)在定義檢出限的時候用了三個比較抽象的數學公式;
1�、臨界值Detection decision (critical value) (LC,α=0.05)
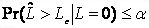
2、檢出限Detection limit (minimum detectable value) (LD,β=0.05)
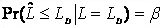
3����、定量限Quantification limit (minimum quantifiable value) (LQ,RSDQ=0.10)
 其中KQ=1/ RSDQ=10
其中KQ=1/ RSDQ=10
要理解以上抽象的數學公式可以用圖1,2加以說明(其中I型錯誤和II型錯誤分別用黑色和灰色表示):

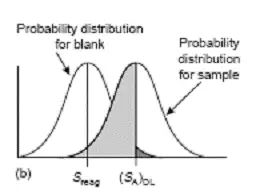
圖1 臨界值的示意圖
對于空白測定的結果可以用圖1中a表示���,我們首先的目的是找到比空白大的一個臨界值(SA)DL����,顯然空白的大部分都比臨界值(SA)DL比小����,但實際還是有黑色的小部分比我們劃定的臨界值要大����,這就是I型錯誤��。早期Kaiser就是用此臨界值作為方法檢出限���,但此時II型錯誤高達50%(見圖1中b)。
后來�,Currie完善了檢出限的統計完備性,采用α=β=0.05來規定檢出限�����,這時候我們可以用圖2來表示����。即規定α=β=0.05錯誤概率,我們對于檢出限的理解依然還是定性的檢出����。要想準確定量樣品中的濃度,必須還要減小錯誤概率��,定量限采用限定RSDQ為0.10方法��,此時的錯誤概率遠遠小于0.05。
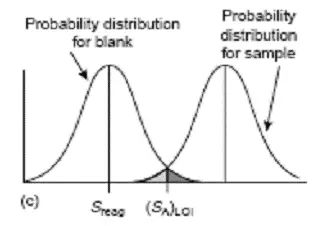
圖2 檢出限示意圖
統一檢出限的相關概念��,完善檢出限的統計完備性都是相對比較容易的事情��。
現有檢出限的爭論��,分歧主要在于以下幾個方面的問題:
1����、空白。
空白的定義本身就有很大的歧義�����,采用什么樣的空白來評價檢出限必然帶來檢出限的差異�����,例如《全球環境監測系統水監測操作指南》采用零濃度樣品來定義空白�,也有用試劑空白的,還有用加標的空白樣品的�。理論上講,*好的空白是零濃度樣品�,但實際工作很少能找到這樣的東西。還有更為郁悶的情況�����,空白進入儀器后只顯示0,這樣的話你就沒辦法評價空白的標準偏差�����,更無法計算檢出限了���。
2、分布的正態假設和置信概率的隨意性���。
現有的檢出限理論都采用正態近似的假設��,但實際測定中空白的分布不一定滿足正態���。不同的人對置信概率把握不同,必然帶來同一實驗不同的檢出限結果����。
3、從信號域到濃度域推算����。
由于我們得到的多數是信號域的空白分布特性���,如何從信號域換算濃度域的檢出限也是爭論很多的問題。是采用標準曲線推算靈敏度呢����?標準曲線又該如何設置呢?還是用較低濃度的CRM來做單點校正�?